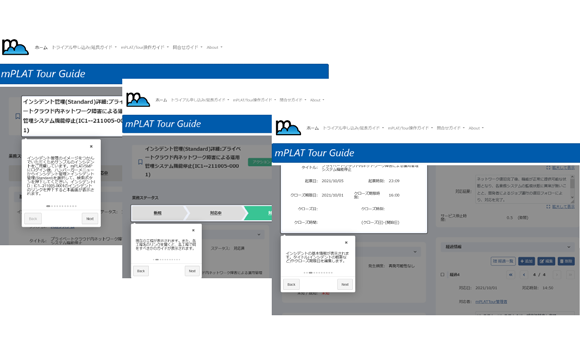
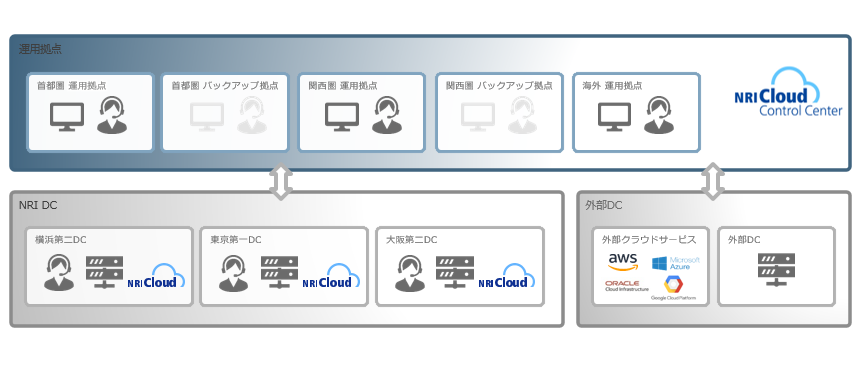
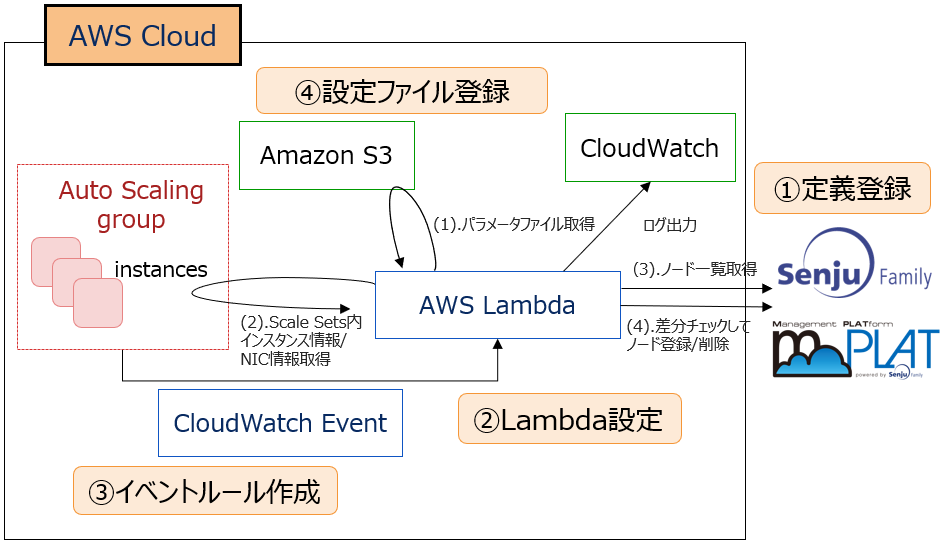
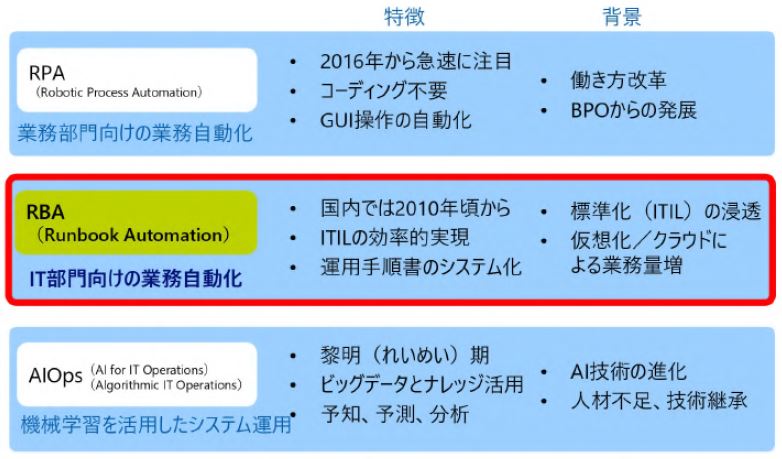
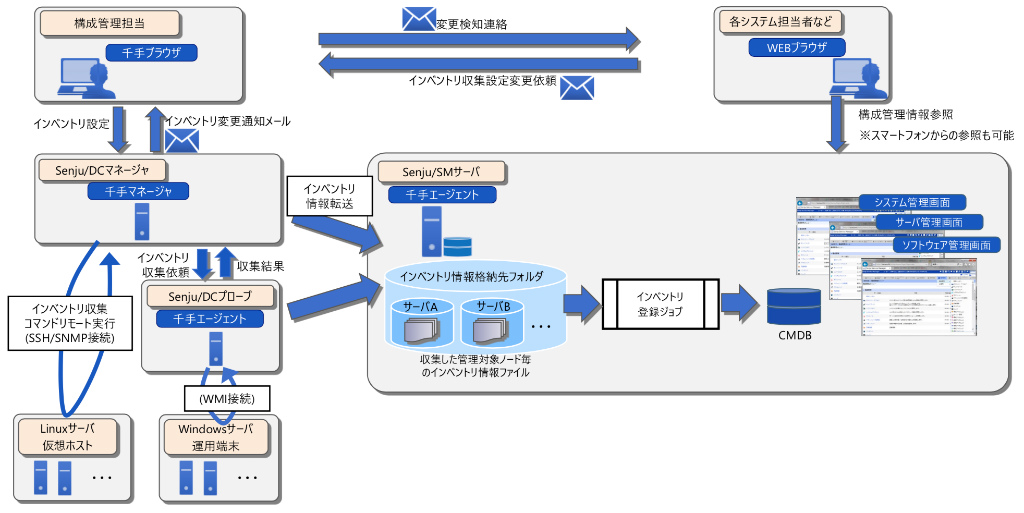
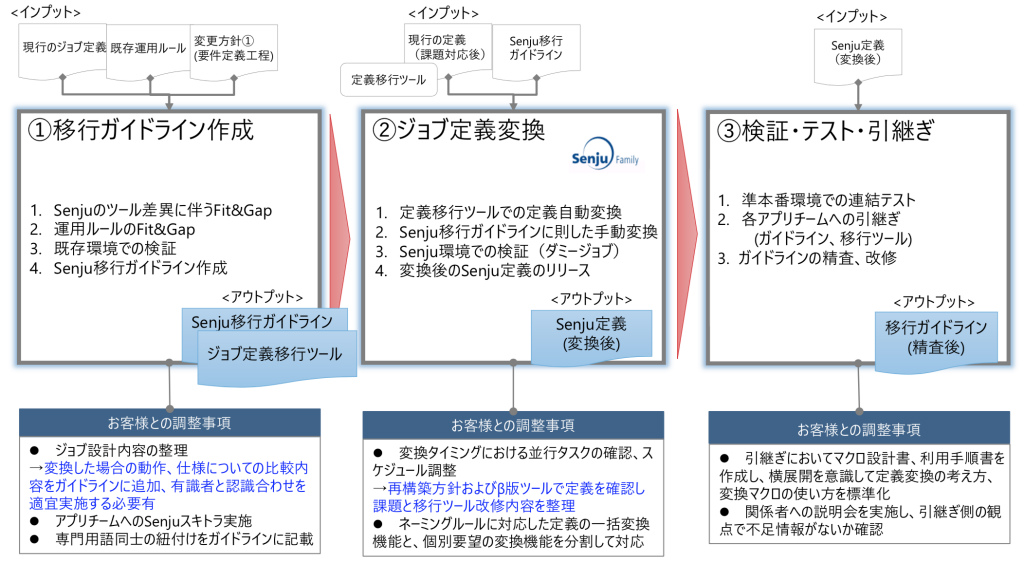
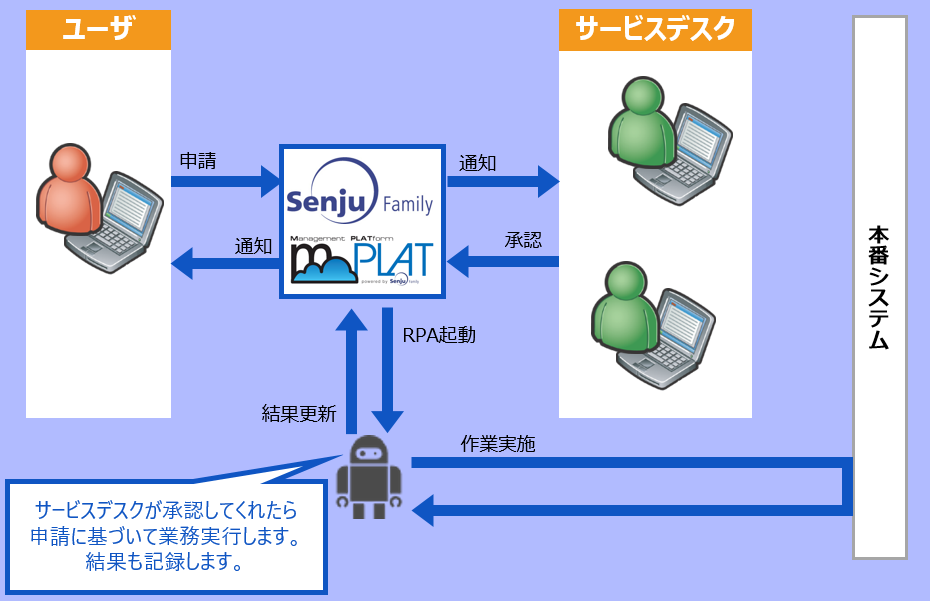
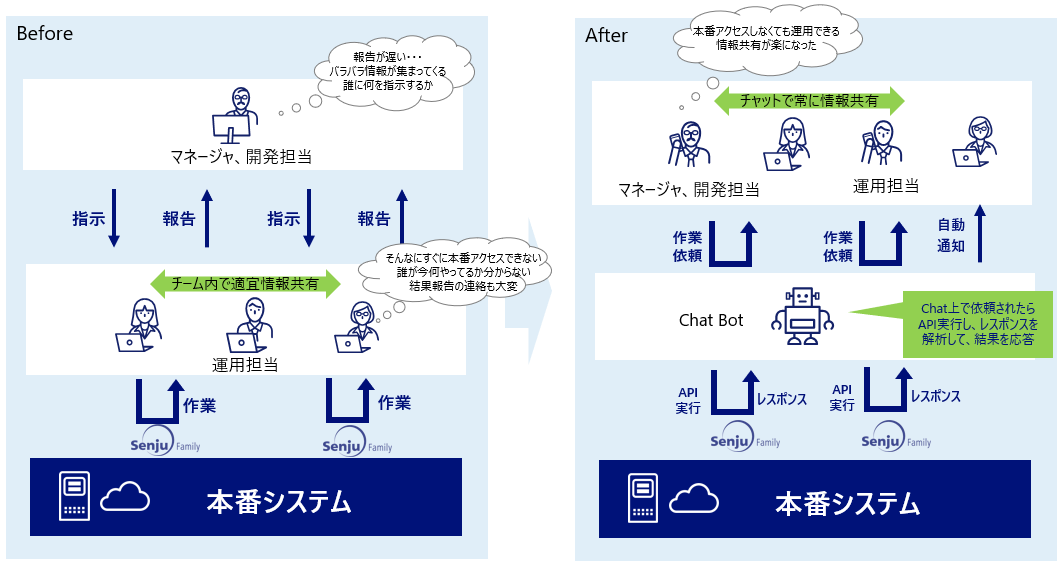
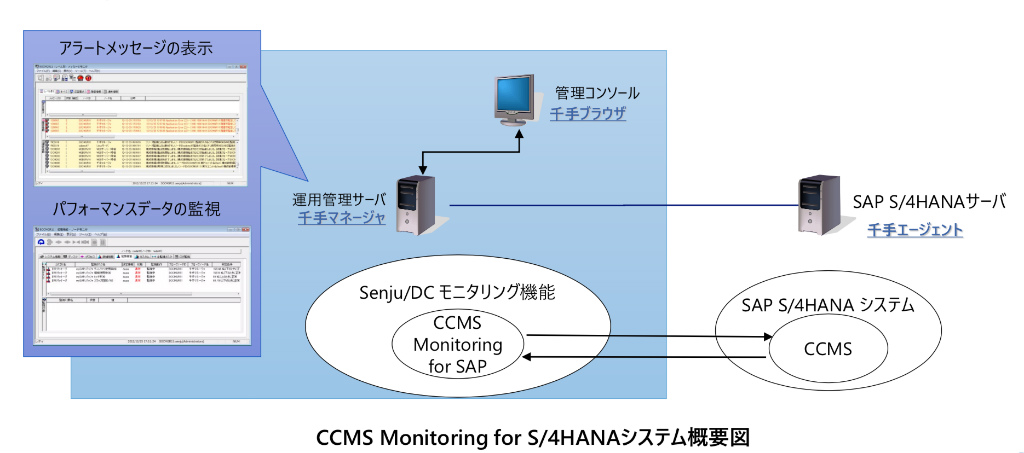
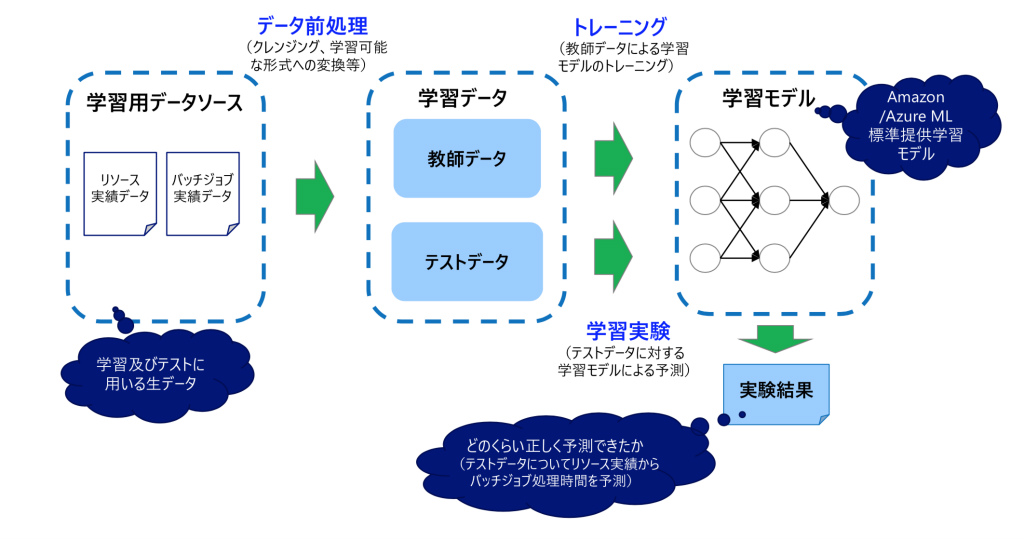
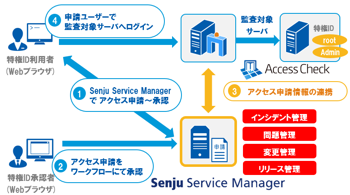
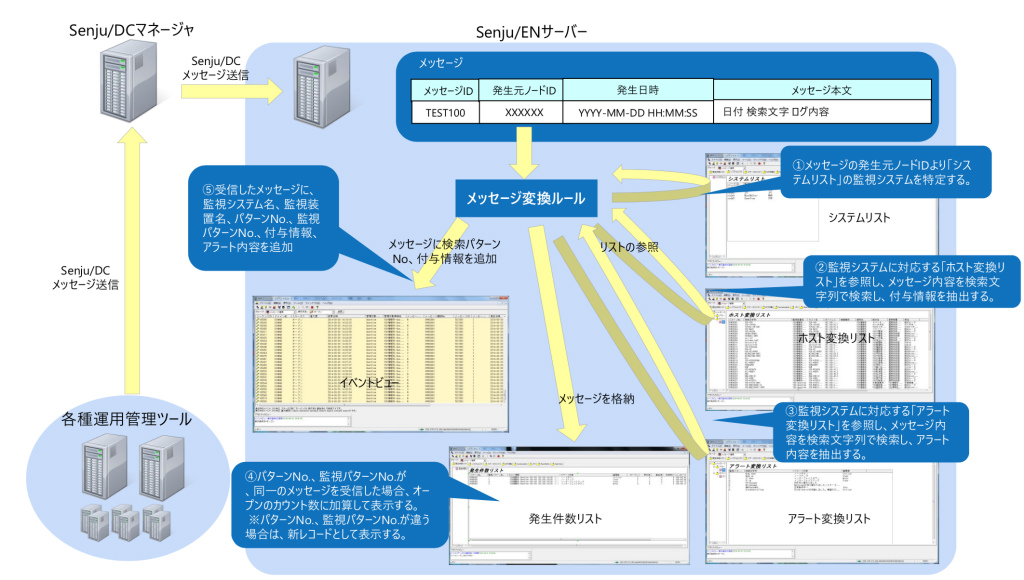
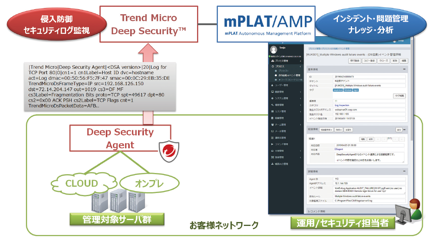
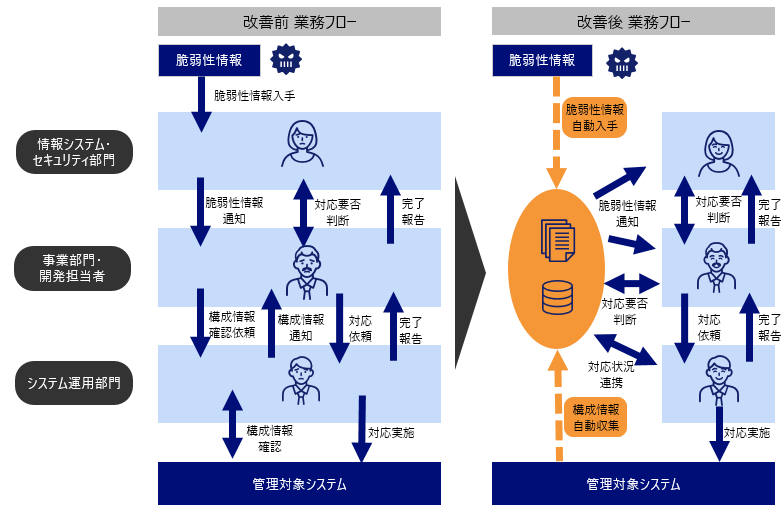
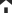運用の悩みを解決するSenju Familyソリューション マルチクラウド管理 マルチクラウドやコンテナ基盤をExtension Packで管理/運用 詳しく見る mPLAT/Tour ガイドに沿ってSenju Family・mPLATを気軽にトライアル 詳しく見る OCI連携 Oracle Cloud InfrastructureをmPLATで管理/運用 詳しく見る MDC運用サービス クラウドやデータセンターのシステムを遠隔拠点より運用 詳しく見る オートスケール連携 クラウドのスケールアウト、スケールインに自動対応 詳しく見る システム運用の自動化 システム運用の自動化はRPAよりもRBA(ランブック・オートメーション) 詳しく見る ITSM可視化 短周期のPDCAを実現するITサービスマネジメントの評価・分析 詳しく見る 構成管理 構成管理はITSMの土台、定着化のカギは情報収集の自動化 詳しく見る ジョブ管理ツール統合 ジョブ管理ツールの統合手順と事例をご紹介 詳しく見る RPA連携 ITSMツールとRPAツールの連携で、統制と自動化を両立 詳しく見る ChatOps Chatにてシステム状況を確認し、Chatから一次対応を実行 詳しく見る SAP HANA連携 S/4 HANAのジョブ管理と、CCMS連携で運用自動化 詳しく見る バッチジョブ遅延予測 機械学習の活用により、バッチジョブの遅延を予測 詳しく見る 特権ID管理 利用申請から承認、アクセス、クローズまでを一元管理 詳しく見る 監視メッセージ統合 監視ツールに手を加えることなく、監視メッセージを統合 詳しく見る Trendmicro DS 連携 Deep Securityとの連携により、発見的セキュリティ対策を実現 詳しく見る mPLAT/Clouday Quick Board マルチクラウド環境・コスト状況をすぐに可視化 詳しく見る 脆弱性対策 構成管理とプロセス管理で脆弱性対策を迅速化 詳しく見る Syntheticモニタリング 外形監視でサービス品質を常時モニタリング 詳しく見る 業務ロジックアドオン 外部ツールと連携しサービスデスク業務を効率化 詳しく見る 資料請求・お問い合わせはこちら 資料請求・お問い合わせ